semantic_segmentation
Semantically segment the road in the given image.
Road Segmentation
Objective
In the case of the autonomous driving, given an front camera view, the car needs to know where is the road. In this project, we trained a neural network to label the pixels of a road in images, by using a method named Fully Convolutional Network (FCN). In this project, FCN-VGG16 is implemented and trained with KITTI dataset for road segmentation.
Demo

(click to see the full video)
1 Code & Files
1.1 My project includes the following files and folders
- main.py is the main code for demos
- project_tests.py includes the unittest
- helper.py includes some helper functions
- env-gpu-py35.yml is environmental file with GPU and Python3.5
- data folder contains the KITTI road data, the VGG model and source images.
- model folder is used to save the trained model
- runs folder contains the segmentation examples of the testing data
1.2 Dependencies & my environment
Miniconda is used for managing my dependencies.
- Python3.5, tensorflow-gpu, CUDA8, Numpy, SciPy
- OS: Ubuntu 16.04
- CPU: Intel® Core™ i7-6820HK CPU @ 2.70GHz × 8
- GPU: GeForce GTX 980M (8G memory)
- Memory: 32G
1.3 How to run the code
(1) Download KITTI data (training and testing)
Download the Kitti Road dataset from here. Extract the dataset in the data folder. This will create the folder data_road with all the training a test images.
(2) Load pre-trained VGG
Function maybe_download_pretrained_vgg() in helper.py will do
it automatically for you.
(3) Run the code:
python main.py
(4) Use my trained model to predict new images
You can download my trained model here
and save it to the folder model. Also, you need to set the training flag to False
in the main.py:
training_flag = False
Then run the code by:
python main.py
1.4. Release History
- 0.1.1
- Updated documents
- Date 7 December 2017
- 0.1.0
- The first proper release
- Date 6 December 2017
2 Network Architecture
2.1 Fully Convolutional Networks (FCN) in the Wild
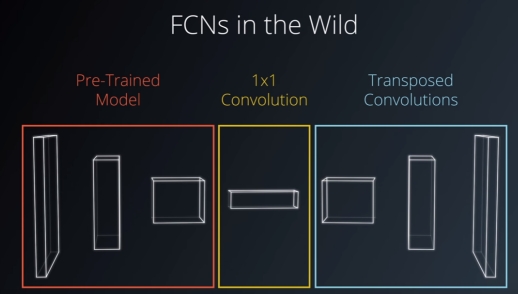
FCNs can be described as the above example: a pre-trained model, follow by 1-by-1 convolutions, then followed by transposed convolutions. Also, we can describe it as encoder (a pre-trained model + 1-by-1 convolutions) and decoder (transposed convolutions).
2.2 Fully Convolutional Networks for Semantic Segmentation
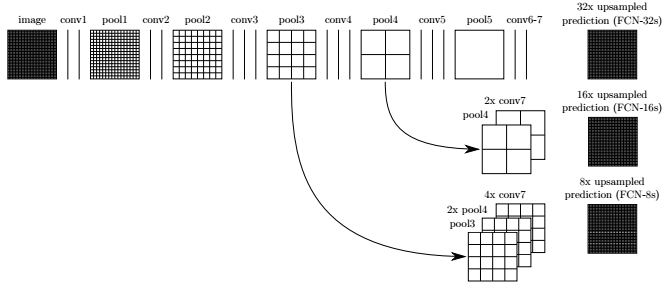
The Semantic Segmentation network provided by this paper learns to combine coarse, high layer informaiton with fine, low layer information. The pooling and prediction layers are shown as grid that reveal relative spatial coarseness, while intermediate layers are shown as vertical lines
- The encoder
- VGG16 model pretrained on ImageNet for classification (see VGG16 architecutre below) is used in encoder.
- And the fully-connected layers are replaced by 1-by-1 convolutions.
- The decoder
- Transposed convolution is used to upsample the input to the original image size.
- Two skip connections are used in the model.
VGG-16 architecture
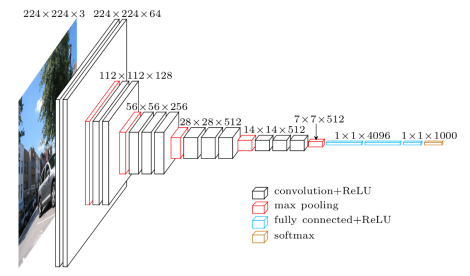
2.3 Classification & Loss
we can approach training a FCN just like we would approach training a normal classification CNN.
In the case of a FCN, the goal is to assign each pixel to the appropriate class, and cross entropy loss is used as the loss function. We can define the loss function in tensorflow as following commands.
logits = tf.reshape(input, (-1, num_classes))
cross_entropy_loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits, labels))
Then, we have an end-to-end model for semantic segmentation.
3 Dataset
3.1 Training data examples from KITTI
Origin Image

Mask image

In this project, 384 labeled images are used as training data. Download the Kitti Road dataset from here.
3.2 Testing data
There are 4833 testing images are processed with the trained models. 4543 frames from are a video and other 290 images from random places in Karlsruhe.
4 Experiments
Some key parameters in training stage, and the traning loss and training time for each epochs are shown in the following table.
epochs = 37
batch_size = 8
learning_rate = 0.0001
| epochs | learning_rate | exec_time (s) | training_loss |
|---|---|---|---|
| 1 | 0.0001 | 43.16 | 0.7978 |
| 2 | 0.0001 | 38.52 | 0.5058 |
| 3 | 0.0001 | 38.55 | 0.2141 |
| 4 | 0.0001 | 38.56 | 0.1696 |
| 5 | 0.0001 | 38.39 | 0.1339 |
| 6 | 0.0001 | 38.44 | 0.1215 |
| 7 | 0.0001 | 38.68 | 0.1089 |
| 8 | 0.0001 | 38.3 | 0.0926 |
| 9 | 0.0001 | 38.14 | 0.0913 |
| 10 | 0.0001 | 38.08 | 0.0837 |
| 11 | 0.0001 | 38.34 | 0.0703 |
| 12 | 0.0001 | 38.02 | 0.0663 |
| 13 | 0.0001 | 38.21 | 0.0585 |
| 14 | 0.0001 | 38.33 | 0.0549 |
| 15 | 0.0001 | 38.12 | 0.0525 |
| 16 | 0.0001 | 38.31 | 0.0483 |
| 17 | 0.0001 | 38.4 | 0.0465 |
| 18 | 0.0001 | 38.42 | 0.0454 |
| 19 | 0.0001 | 38.27 | 0.0421 |
| 20 | 0.0001 | 38.73 | 0.0404 |
| 21 | 0.0001 | 38.03 | 0.039 |
| 22 | 0.0001 | 38.22 | 0.0387 |
| 23 | 0.0001 | 37.95 | 0.0368 |
| 24 | 0.0001 | 38.22 | 0.0352 |
| 25 | 0.0001 | 38.91 | 0.0335 |
| 26 | 0.0001 | 38.67 | 0.0324 |
| 27 | 0.0001 | 38.21 | 0.0316 |
| 28 | 0.0001 | 38.2 | 0.0302 |
| 29 | 0.0001 | 38.13 | 0.0291 |
| 30 | 0.0001 | 38.19 | 0.0313 |
| 31 | 0.0001 | 38.15 | 0.0303 |
| 32 | 0.0001 | 38.16 | 0.0299 |
| 33 | 0.0001 | 38.11 | 0.0273 |
| 34 | 0.0001 | 38.21 | 0.0265 |
| 35 | 0.0001 | 38.16 | 0.0254 |
| 36 | 0.0001 | 38.62 | 0.0244 |
| 37 | 0.0001 | 37.99 | 0.0234 |
5 Discussion
5.1 Good Performance
With only 384 labeled training images, the FCN-VGG16 performs well to find where is the road in the testing data, and the testing speed is about 6 fps in my laptop. The model performs very well on either highway or urban driving. Some testing examples are shown as follows:





5.2 Limitations
Based on my test on 4833 testing images. There are two scenarios where th current model does NOT perform well: (1) turning spot, (2) over-exposed area.
The bad performance at the turning spots might be caused by the fact of lacking training examples that from turning spots, because almost all the training images are taken when the car was driving straight or turning slightly. We might be able to improve the performance by adding more training data that are taken at the turning spots. As for the over-exposed area, it is more challenging. One possible approach is to use white-balance techniques or image restoration methods to get the correct image. The other possible approach is to add more training data with over-exposed scenarios, and let the network to learn how to segment the road even under the over-expose scenarios.
Turning spot

Over-exposed area
